As part of our suite of data validation products here at Service Objects, we offer three main phone services: Geophone Plus (reverse lookup), Phone Exchange, and Phone Append. Depending on...
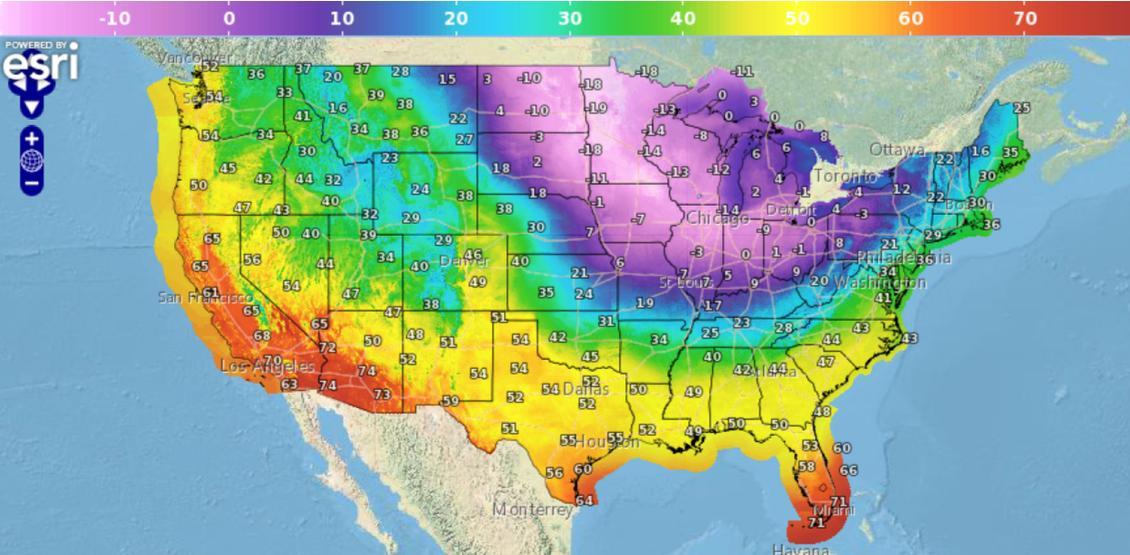
With large parts of the US dealing with the #PolarVortex, the focus is rightly on keeping people safe and critical systems continuing to operate. The impacts are already far-ranging, from...
Perhaps Thomas Redman’s most important recent article is “Seizing Opportunity in Data Quality.” Sloan Management Review published it in November 2017, and it appears below. Here he expands on the “unmeasured”...
Engaged employees lead to happy customers. There is an undeniable link between employee experience and customer experience. Companies that lead in customer experience have 60% more engaged employees, and study...
I published the provocatively-titled article, “Bad Data Costs the United States $3 Trillion per Year” in September, 2016 at Harvard Business Review. It is of special importance to those who...
“Online retailers of all sizes are constantly under attack by sophisticated fraudsters. In fact, credit card fraud costs US online retailers an estimated $3.9 billion each year.” – Geoff Grow, Founder...
In today’s fast-paced world, customers have become more demanding than ever before. Customer-centric organizations need to build their models after critically analyzing their customers, and this requires them to be...
There are a lot of buzzwords thrown around in the customer sphere, but two of the big ones relate to experiences—customer and user. Although CX and UX are different and...
According to a recent blog by Villanova University, the amount of data generated annually has grown tremendously over the last two decades due to increased web connectivity, as well as...