
As a data validation company, we think a lot about how information is collected and stored – and we know that the right approach to data collection can ensure that you start off on the right foot. This blog shares some expert tips for channeling your data into your company’s data stores, in ways that give you the best chance to have this data corrected, standardized, and validated.
Let’s imagine a few of the most common data entry points. At the top of the list we find web forms, compiled datasets, and manual entry from locations such as Point-of-Sale (POS), phone calls, and written transcriptions. Each type of data entry is unique from an interface perspective, but there are still two key rules you can use to limit the chance for errors or garbage. Here they are:
1. Divide and conquer
First, break down your data into its most simple components. By collecting data in its simplest form you can ensure there is no confusion between what the data is supposed to represent and other fields. This is a principle we call separation of data, where each field only contains the most relevant data for its type.
In the best case, you have a collection of very specific fields with unique data types – as opposed to the worst case, where you have a group of identical fields collecting your data. Could a user enter, say, his grandmother’s name in the ZIP code field? If so, you still have some refinement to do here.
2. Set data constraints
Next, determine what characters are relevant to each specific field. For example, if you are collecting “Age” data, you know that the data field should be a number. It doesn’t make sense to allow for anything other than the numbers 0-9 (and please don’t get cute and allow words such as “thirty-five”). Extending your requirements further, you could even limit the “Age” field to positive numbers to prevent someone from claiming they are -5 years old.
Now, let’s put these two rules to work for two of the most common types of contact data: delivery addresses and email addresses.
United States delivery addresses
This is a case where a basic understanding of the data you are collecting will take you a long way. Here we are going to examine the anatomy of a typical US address, as shown in Wikipedia, and then split the individual components into different fields.
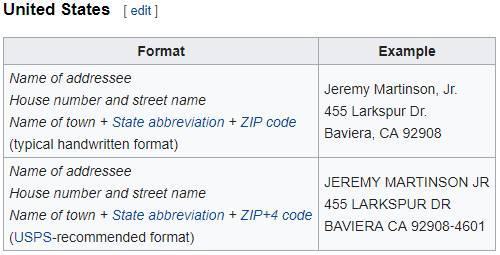
https://en.wikipedia.org/wiki/Address_(geography)#United_States
From this US address example, we can see the recommended USPS format. Within the address, we have the house number and street name (Address1), the name of town (City), the state abbreviation (State), and the ZIP+4 (ZIP/PostalCode).
Here are some good and bad examples of address data:
Ideal input
| Field | Content | Description |
|---|---|---|
| Address1 | 27 E Cota St STE 500 | Contains a mix of alphanumeric data pertaining to the mailbox # and street |
| Address2 | c/o John Smith | Non-critical deliverability information |
| City | Santa Barbara | Contains only alpha characters |
| State | CA | Standard 2 character representation of a state chosen from a list of acceptable values |
| ZIP | 93101 | 5 digit number without extraneous characters |
Address 2 used incorrectly
| Field | Content | Description |
|---|---|---|
| Address1 | 27 E Cota St STE 500 | No issues |
| Address2 | Santa Barbara, CA 93101 | City, state and ZIP are not separated |
Allowing abbreviations and local language
| Field | Content | Description |
|---|---|---|
| Address1 | 27 E Cota St | No issues |
| City | SB | Abbreviating the city name is not ideal. Spell out full name or use ZIP to determine and populate this field |
| State | Cali | Informal spelling instead of California or CA. State should be selected from a data set |
| ZIP | 93101abc | Should be a 5 digits with no alpha characters |
Email addresses
Now let’s turn to the format of an email address, again from Wikipedia:
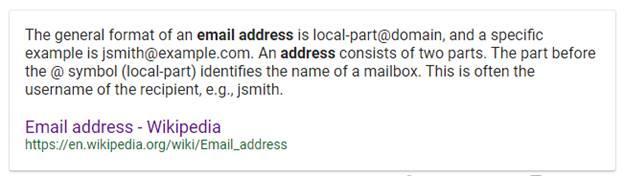
https://en.wikipedia.org/wiki/Email_address
Emails are a bit trickier, but constraints can still be placed on the point of entry. The set of allowed characters in an email is far more expansive than say, postal codes, but there are still limitations. By putting the restrictions in place you can still cut out some of the garbage that can be submitted.
In this case, you could examine the individual elements of an email and place restrictions on each. Since an email must consist of a local-part, “@” symbol, and a domain, it is safe to restrict your collected data to only email inputs that conform to the anatomy of an email. For example, an address such as “Input 1: 123ABCSt.foobar@domain.com Thirty-Five” does not end with a legal domain identifier, and also contains illegal spaces within the address and after the closing period.
General contact record data collection
The same techniques can be applied to all of the data that you collect. Some fields may be easier to apply constraints to, but any attempt to filter acceptable input and organize the data into manageable sections will benefit you down the line. We specialize in data validation and have spent over 15 years refining our methods for interpreting, standardizing, and validating data. If data is gathered in component parts we can at least gain context and, even if the data isn’t correct, apply our specialized knowledge to try and validate this information.
Finally, give some thought to how your data will ultimately be stored in a data store or database. Since this is the bottom level, it is crucial for database administrators to make educated choices about these data fields. If constraints aren’t placed at the database level, the information you have collected could be rendered useless. Smart choices in data type, accepted data length, and constraints can help ensure that your data is stored in its most sensible form.
As with most things in life, an ounce of prevention is worth a pound of cure when it comes to collecting and maintaining contact data accuracy. The techniques described above, in conjunction with Service Objects web services, will help provide you with the most genuine, accurate, and up-to-date data as possible.



