
De-duping data is one of the most popular uses of our services, and for good reasons: duplicated data can lead to redundancy, extra costs, waste and even lack of customer engagement. In this blog post, we will examine a particularly challenging issue: getting rid of duplicate contact names.
De-duping for some data sets can be easier than others. For example, phone and email addresses can be relatively straightforward, as those provide a unique ID to tie back to a customer. We’ve recently published a blog on how to dedupe to addresses with the barcode digits field in our Address Validation – US service, so de-duping validated address data should be a cakewalk.
While de-duping with emails, phone numbers or barcode digits can be relatively straightforward, de-duping names in a database might prove to be a bit more difficult. One of the issues that may present itself is that a database might have several different variations of the same name. For example, the name “John” could come in different variations like Johnny, Jonathan or even slightly mistyped as Jon.
Our DOTS Name Validation is an API that can help with this and provide the tools you need to get rid of duplicate name entries in a database. When a name is processed through Name Validation, we check it against millions of different names to find out if it matches a known name. Because of this, we are able to return several other names that may match one of the variants we’ve found in our database.
Let’s take the name “James Smith” as an example. When this is run through our service it will result in the following response:
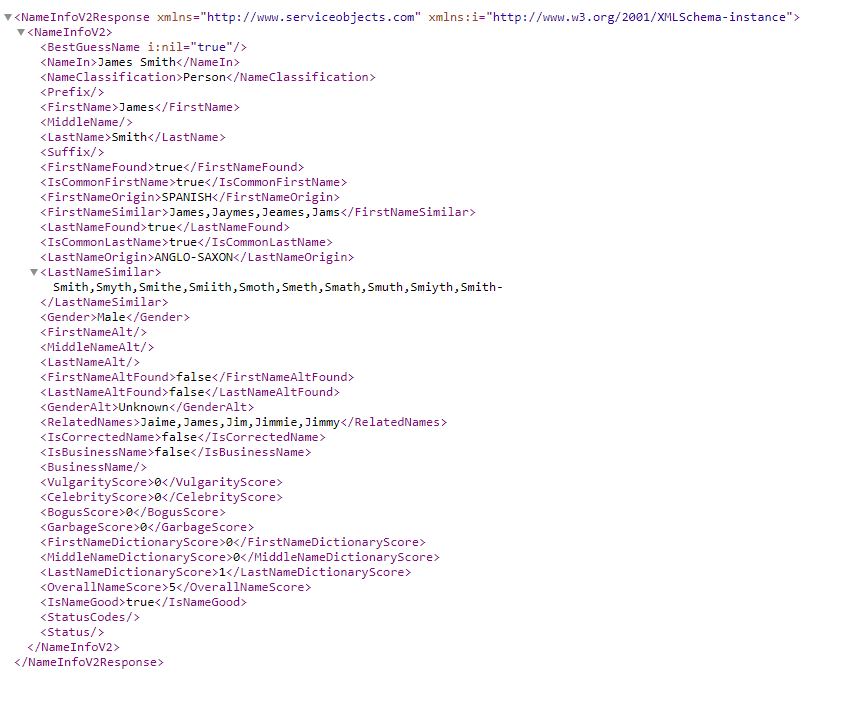
The service returns various pieces of information that can be used to determine the validity of a name, but one of the fields we want to utilize for removing duplicates is the RelatedNames field highlighted below:
![]()
Here we see some common variants of the name “James.” The RelatedNames field will return names that are often associated or variants of the input name. With these, in addition to the last name, you would have the following 5 different combinations of the name you are attempting to find matches for.
Jaime Smith
James Smith
Jim Smith
Jimmie Smith
Jimmy Smith
With these in hand, you can loop through some of the names in your database beginning with the letter “J” and flag any entries that come up with a match. These matches would likely still need a human eye and some more investigation in order to determine if they were actually duplicates, but this will most certainly help reduce the amount of human time involved in looking through duplicate names.
If you wanted to make your search for duplicate names even more aggressive you could use the field FirstNameSimilar to look for other potential duplicates. In our example, this field will return the following highlighted names:
![]()
This field will return other names that are phonetically similar to the first name submitted on the input. These names might be a bit more far-reaching or different from the intended first name, so if you look for matches in your database with these, there is a chance it might flag names that are unique from one another. So using a human eye to review these results is still a good idea.
The LastNameSimilar field will also return last names that are phonetically similar to the input last name. If you are running into cases where you have a lot of duplicate last names you could use this field in the same fashion as noted above. This situation may be less common than the first two presented, as there is less of a chance there would be different variants of a last name as there is with a first name.
With any use case or Service Objects API integration, there are always caveats and special scenarios. If you need some advice or recommendations on how to best integrate our API in your application, please reach out to our Applications Engineering team and we’ll be happy to provide any integration assistance that we can.



