In most CRMs, lead scoring is used to determine the viability and likelihood that a lead will become a paying customer. Generally, lead scores are a sum of points assigned...
In this guide, we’ll illustrate how to create a custom button in a Zoho CRM module that will call our DOTS Lead Validation – International API. Lead Validation – International...
This past year has been a perfect storm for people who do ecommerce. On the good side, business is booming – thanks in large part to a global pandemic, ecommerce’s...
The launch of our new product, DOTS Global Address Complete, has brought along with it a nifty new license key. This new custom key has the necessary security features to...
Therapists validate people’s feelings. Retail stores validate your parking. Health departments validate vital records. But what does it mean to validate an address? According to the Oxford Dictionary, the word...
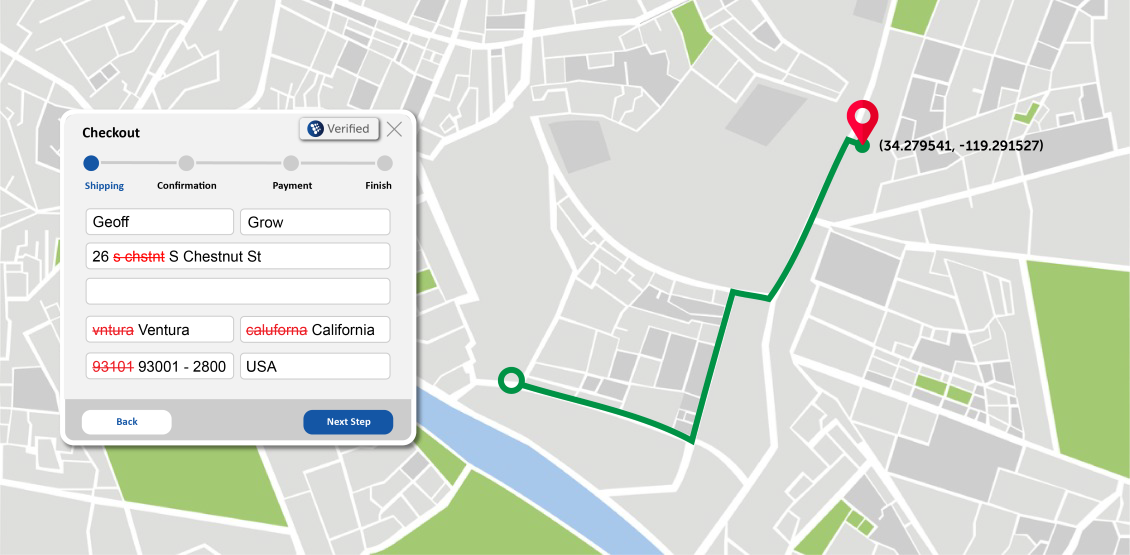
What is Global Address Complete? Service Objects, Inc. has just welcomed our latest service DOTS Global Address Complete into our suite of services! This service suggests addresses in a type-ahead...
Old technology products never die – and sometimes, they don’t even fade away. For example, did you know that according to some estimates, more than 25 million people are still...
DOTS Lead Validation – International is a complex service combining over ten of our other services, as well as unique proprietary algorithms specific to Lead Validation. This service can take...